ise à part un fonctionnement global, les moteurs de recherche ne sont pas tous les mêmes. Il existe ainsi deux types de moteurs, deux modèles : le modèle vectoriel ou probabiliste qu'utilise par exemple Euroferret, et le modèle booléen qu'utilise Altavista et la plupart des autres moteurs.
Le modèle booléen est très répandu au point que presque tous les moteurs sont de ce type.
Le modèle vectoriel est celui qu'utilise le guide Minitel : la requête est une phrase écrite en langage naturel, qui doit être la plus complète et précise possible : elle doit englober tous les aspects du sujet recherché. Ceci dit, rien n'empêche l'utilisateur de formuler sa requête en un seul mot. Le seul désavantage sera une recherche parfois moins précise et donc moins proche de ce que l'utilisateur attends.
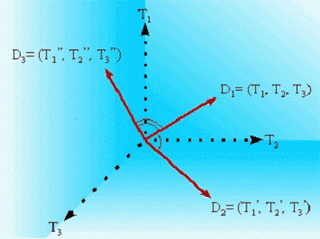
Le modèle vectoriel recherche des réponses en construisant des vecteurs en fonction de la requête. Ce sont des vecteurs au sens mathématique (et non pas des tableaux) qui sont ainsi construits dans un espace en trois dimensions. Cet espace est constitué d'un repère : chaque vecteur part de l'origine de ce repère, et prend une certaine direction suivant le poids de chaque terme défini préalablement par le moteur ou parfois par l'utilisateur. Le poids est comme son nom l'indique une "mesure" qui permet au moteur de reconnaître les termes en fonction de leur importance dans la requête. Cette importance est définie suivant des critères spéciaux que l'on ne peut pas connaître.
En trois dimensions, quand trois termes sont censés identifier un document, chaque axe du repère correspond à un terme différent et la
position de chaque vecteur du document dans l'espace est déterminée par la grandeur du poids des termes de ce vecteur. La similitude entre deux vecteurs est représentée comme fonction inverse associée à l'angle de ces deux vecteurs. Ainsi, quand deux vecteurs du document sont les mêmes, les vecteurs sont superposés et l'angle que font les deux vecteurs est nul. Le moteur a donc pour tâche principale de calculer les angles entre les vecteurs pour pouvoir ensuite savoir si un document peut constituer une réponse valable.
Le modèle vectoriel comporte plusieurs avantages : les documents peuvent être rangés par ordre décroissant de similarité avec la question rendant possible la visualisation par ordre décroissant d'importance dans l'esprit de l'utilisateur des articles retrouvés. De plus, le nombre d'articles retrouvés peut être adapté en fonction des exigences de l'utilisateur, en ne retrouvant que les premiers de la liste pour des utilisateurs occasionnels et en retournant un groupe plus complet de réponses pour des utilisateurs spécialisés qui attendent une bonne performance de la part du moteur. Les premiers articles retrouvés sont ceux qui correspondent le mieux à la requête, cela pouvant aider à reformuler la question pour améliorer la performance du retour.
Le modèle de recherche booléen est le plus utilisé. Il recherche des documents par rapport à des mots clés, liés ou non entre eux par des opérateurs booléens. Ces opérateurs sont les mêmes qu'utilise l'algèbre de Boole, à savoir le "and", le "or" et le "not". Toutes les opérations que permet l'algèbre de Boole sont possibles lorsque l'on formule une requête.
L'opérateur "or" traite les deux mots clés comme synonymes, bien qu'ils ne le soient pas forcément dans l'esprit de l'utilisateur. La recherche aboutit à une réponse quand l'un des deux termes (ou les deux) se trouve dans un document.
L'opérateur "and" suppose que l'on veuille retrouver dans le document les deux termes à la fois : les deux ou plusieurs termes de la requête reliés par des "and" doivent impérativement tous être retrouvés dans un document pour que celui-ci constitue une réponse. Cet opérateur est très pratique quand on veut limiter une recherche, par exemple quand le premier mot clé a beaucoup d'homonymes susceptibles de fausser le résultat attendu par l'utilisateur.
Enfin, l'opérateur "not" exclu un document s'il contient les deux termes reliés. Seul le terme, se trouvant avant le "not", doit figurer dans le document, et le terme se trouvant à droite du "not" ne doit pas y être. En fait, le "not" est souvent associé au "and", et peut théoriquement être associé au "or". Lorsqu'il se trouve entre deux termes, le "not" fonctionne que si il est associé. En première position de la requête, le "not" ne doit en revanche pas être associé.
La mise en œuvre assez simple du modèle booléen est certainement l'une des raisons de son énorme succès face au modèle vectoriel : on imagine facilement le "squelette" de l'algorithme de recherche d'un moteur booléen, alors que même si l'implémentation des deux modèles ne diffère pas beaucoup, il est plus difficile à imaginer l'algorithme d'un moteur vectoriel. En fait, le moteur booléen est plus intuitif à programmer. Une autre raison du succès est que le modèle booléen est plus rapide car le programme n'a pas besoin de calculer de nombreux cosinus, opérations assez "longues" surtout quand elles sont répétées de nombreuses fois.
En revanche, si le moteur booléen est plus intuitif à programmer, il ne l'est pas forcément pour les utilisateurs qui préfèrent certainement poser une question dans leur langage qu'avec des opérateurs qu'ils ne savent pas toujours utiliser. Mais ce n'est pas l'utilisateur qui décide... De plus, rien ne l'empêche de formuler de telles phrases avec un moteur booléen, mais les résultats pourraient ne pas correspondre du tout l'attente.