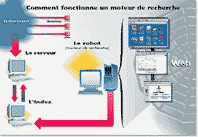
orsque l'on formule une requÍte, on interroge une base de donnťe qui contient des millions d'adresses classťes par thŤmes, mots clťs, avec parfois un descriptif ou simplement les trois ou quatre premiŤres lignes du document. Cette base est rťguliŤrement mise ŗ jour et peut augmenter en taille de deux faÁons :
d'une part tout utilisateur qui dťsire y faire figurer un document qu'il a conÁu remplit un formulaire et sa page fait alors partie de la base de donnťes du moteur ;
d'autre part, ŗ tout instant, des robots parcourent le web et renvoient le contenu de leurs recherches.
Les robots consistent en l'association de deux logiciels : un robot de collecte, que l'on dťsigne aussi en anglais par des termes suggestifs comme crawlers, worms ou spiders..., qui se charge de collecter automatiquement les donnťes disponibles sur les serveurs, et un moteur de recherche qui, ŗ partir de l'analyse textuelle des documents que le robot de collecte a trouvťs, les indexe pour constituer une base de donnťes de rťponses.
En fonction des moteurs, un "jury" dťtermine quels sont les documents qui doivent se trouver dans la base de donnťes du moteur, ils font parfois une sťlection en ťliminant les documents qui selon eux ne conviennent pas ou ne sont plus opťrationnels. Ces moteurs ne sont en fait pas rťellement des moteurs de recherche, mais sont plutŰt appelťs listes ou rťpertoires (directory en Anglais).
En ce qui concerne Altavista (par exemple), il n'y a pas de telle sťlection. Il constitue alors bien un vrai moteur de recherche.
C'est le moteur, qui en partant des mots-clťs de la requÍte de l'utilisateur, recherchera dans la base (en s'appuyant sur l'indexation) les documents contenant ces mots de faÁon significative. Selon les moteurs, les rŤgles utilisťes pour crťer la base de donnťes contenant les rťponses sont trŤs diverses, et souvent peu dťtaillťes par les concepteurs.
Certains moteurs n'utilisent qu'une partie des documents pour dťfinir quelles seront les rťponses : ce peut Ítre, les titres, les sous titres, les "n" premiers mots du document, les "n" premiŤres lignes... Cependant, beaucoup d'outils sont dits "texte intťgral", c'est ŗ dire qu'ils utilisent l'ensemble du document pour ťventuellement l'indexer. En fait, il y a plusieurs degrťs dans cette notion : par exemple, beaucoup de moteurs ťliminent d'abord du texte toute une sťrie de termes trop frťquents, ou simplifient les formes grammaticales.
Le robot peut-Ítre comparť ŗ un ensemble de plusieurs dizaines de navigateurs qui, simultanťment, interrogent les sites Web
Les pages nouvelles trouvťes sont expťdiťes ŗ la machine qui construit l'index. Scooter, le robot d'Altavista, explore 30 ŗ 40 nouveaux liens par seconde.
A partir des pages explorťes par le robot, cet ordinateur construit un index oý sont stockťs ŗ la fois les mots, la position de ces mots dans le document, et la position de ces mots les uns par rapport aux autres. Dans le cas d'Altavista, c'est le mÍme programme qui b‚tit l'index et rťpond aux requÍtes des utilisateurs.
Ce serveur Web joue l'intermťdiaire entre les utilisateurs et l'index. Il transmet les requÍtes des premiers au second, il y a ainsi chaque jour des millions de requÍtes.